Can BODS handle caching the table of size above 2 GB in table comparison?
In my data flow, I am caching a table which has 4 miilions records and data flow fails with error.
10876 19876 SYS-170114 19.06.2012 09:52:28 Warning: Your system is running low on process virtual memory space. Available virtual memory is <23> megabytes.
I am monitoring the data flow on the server while running it and I see the process reaches of memory usage 2 GB and it get terminate and job fails.
Why data flow is not doing paging but it is saying in the logs…
9472 19560 DATAFLOW 19.06.2012 11:14:30 Sub data flow <EDW_VW_PaymentReminder_SE_3> using PAGEABLE Cache with <1419 MB> buffer pool.
PS: it works good with Sorting order in Table comparison.
Also, Version 12.2.3.4 has issue with Table comparion with sorting order. Query issued to data base is waiting infinitely. We have to kill the data flow and runs again and it works fine.
I dont’ think the cached comparison method is a good fit for your Dataflow. That method should be used when the number of rows in the comparison table are small. Think 10,000 rows.
Data Services is telling you that it isn’t going to cache 4 million rows. I would expect way better performance using one of the oher comparison methods depending on what your input schema looks like.
We are struggling with TC with Sorted input issue in 12.2.3.4. So we were testing if in the worst case scenario if we can use cache comparison table.
I also tried to change the Dsconfig file (PAGEABLE_CACHE_BUFFER_POOL_SIZE_IN_MB=1500) to use pageable cache but my data flow doesnt use pageable cache and still failing if cache is above 2 Gb. I dont know how can i make work pageable cache for data above 2 GB.
Please provide more information. How many input rows, how many rows in the comparison table, perhaps some DDL, what are the primary keys as defined in the table comparison transform, etc.
Issue description: Data flow using Table Comparison method as sorted input is hanging for forever.
Issue detail:
Data flow which has table comparison transformation with sorted input, is issuing the query to sort the data from TC irrespective to source has no records to process. This process, Source transformation has zero records to process but TC has issued query to DB to sort the record to compare is running infinitely.
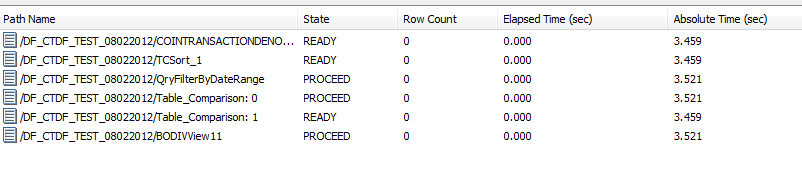
Following 4 pics shown the stating the process, data flow, monitor log, Data base query and status.
Why TC transformation is issuing the query if no records in source transformation and why is it not ending the process?
I have attached the snapshot in the docs. Any help would be highly appreciated.
I was expecting to see a WHERE clause in the Table Compare Reader query - I’m not sure why it isn’t there. But I wasn’t expecting to see TWO table comparison transforms in the same Dataflow. That is very unusual. Without getting into the logic of your Dataflow I’ll say that when I see something like this my first impression is that the developer doesn’t quite know how to efficiently use a Dataflow or is trying to cram too much processing into a single Dataflow.
The Dataflow appears to be in a wait state. It’s waiting on the Database for something but I’m not convinced that it’s the Table Comparison that it is waiting on.
Try breaking the Dataflow up into smaller Dataflows. At the very least that will give you an idea of where the actual bottleneck is.
Instead of two target tables (the same table even!) use a Merge to bring the two branches back together and that way you have one connection applying inserts and updates. For this example you’ve shown the two branches/target tables shouldn’t matter since no rows are being processed. But what happens when you have a large number of rows to insert/update?
I agree with you on inefficient design of the data flow but this is same issue in many data flows where we have only one table comparison.
I actually took very simple data flow with no records from source but table comparison and it was hanging on table comparison and also noticed always that there is not where condition.
Does the compare table have no indexes? Does the imported metadata in the Datstore reflect the indexes and/or primary key? The index or primary key needs to match the primary key columns defined in the Table Comparison transform. That could be why no WHERE clause is defined in the table compare reader query.
I’ve recently encountered the same thing, I have a very simple data flow, where source table is a staging table with 0 rows and destination table is a fact table with a table comparison transformation. Data flow looks like this:
StgTbl ->Qry → Table Comparison (sorted input) → Target table
When the source staging table has rows, this flow executes with no problem, however, when there are no rows in the staging table this process just hangs forever and eventually I need to kill it. I checked the database and there are no blocked processes, so there is something going on in DS. I’ve recently upgraded the DS to the latest DS 4 SP3 version (I wonder if it has anything to do with that, since I don’t remember experiencing this issue before).
I’ve attached the Data Services monitor log for the TC data flow.
Before you open a support ticket turn on SQL tracing so you can see the exact queries that are being submitted to the database. The table compare reader query is the one I think you’ll need to focus on.
Based on your attached monitor log it looks like the Dataflow is sorting the compare table on the job server. That would be very odd for it to do that. I’m basing that on the TCSort_1 item. It’s been a while since I dug into what a table compare is doing behind the scenes so I could be wrong.
If the SQL trace shows a query against the compare table that has no WHERE clause and no ORDER BY clause then something is off. It should have an ORDER BY unless the compare table has a clustered index (SQL Server) or is index organized (Oracle) and the primary keys in the Table Compare match that index and the Table Compare tranform is smart enough to make the connection. That’s giving it a lot of credit and I doubt that it does that. So an ORDER BY should be there.
Cached comparison table can be larger than 2Gb – pageable cache should “kick in”. It’ll just be really really slow, when it works. In your case, it’s not working properly.
In our experience, some designs or features can prevent pageable cache from working properly. Do you have a lookup() function somewhere in the dataflow? (Not lookup_ext, but rather lookup). That could cause it. Please post the ATL and we can look at it.
In looking at the picture of your dataflow, I am guessing the TC_Insert and TC_Update table compares are both pointing to the same table, and of course you have the same target table in there twice. I can say right off the bat, this will be a fragile design. Try to redesign using data transfers and other methods to get to a single table compare and a single target table.
I have looked at this dataflow as well now and many things I recognize immediately
Max_PK in update: I guess you have a surrogate key in the target and potentially multiple versions and you want to update juts the latest? Table Comparison does exactly that when specifying the generated_key column.
Case for insert or update: Table Comparison does that anyhow.
Feed insert rows through a Key_Gen transform but updates not: Again, Key_Gen does that. It generates keys for rows flagged as insert by the Table Comparison transform but update rows it keeps as is.
So at the moment I’d say the entire dataflow can be changed to a
Regarding the locks all of these might be read locks caused by somebody else updating the table in SQL Server. Enabling dirty reads might do the trick.
Thank you for your quick reply and for pointing me in the right direction. I did find out the problem. Since I had the comparison method in the Table comparison transform as sorted input, it is trying to sort the target fact table (which has billions of records). However since I have 0 records in the input table, the select has no where clause (it does however have an Order by), so it attempts to sort the entire fact table, and this is why the process shows as hanged and takes forever.
This seems like a bug to me, it should not sort the target table if the input table has 0 rows, should simply skip over the step and finish successfully. This seems to be a regression bug introduced in SP3, since I’ve checked my process prior to the upgrade that I did recently, and the same scenario worked fine.
In the short term I’ve changed the comparison method to row_by_row select which solved the problem, but this is not ideal. I will probably submit a support ticket for SAP.
Woo hoo!! Thanks for the feedback. It’s good to know I was on the right track and that you have a suitable work around. I agree that this is a bug. The Table Compare transform should recognize that there are no rows in the input schema and skip looking at the compare table.
I can think of a couple of alternative work arounds that would allow you to keep the sorted intput option. Let me know if you’re interested.
Using the row_by_row select is extremely slow for this data flow compared to the sorted_input I used before, so I may change it to break out the process into two different data flows (depending on the input table: has rows vs no rows).
I opened a support ticket with SAP and I can update the thread when I hear back.
Stick a dummy row (with a very high PK value that would never be seen in the compare table) in the input table if there are no rows in the input table. Then in the load Dataflow filter out the dummy row (which would always be an insert) after the Table Compare. That way you don’t need two Dataflows (one for no rows and one for has rows).
 (BOB member since 2007-09-12)
(BOB member since 2007-09-12) (BOB member since 2004-12-17)
(BOB member since 2004-12-17)