I want to update two tables together and either commit the changes to both or roll them back.
My understanding is that checking “Include in Transaction” on both target tables should achieve this as long as the tables are from the same datastore, which they are.
The problems I get are
a) I get an error saying that I have to set the sequence number if I leave the Transaction order fields blank
b) After I have set the sequence number / Transaction order and I get an error in the load of the second table the updates to the first are not rolled back.
Yes, you have to set a transaction order, otherwise it is a syntax error.
But then, if you are really really really using one datastore for both tables it should work. What’s the error message you get? Turn the trace options “trace sql loader” and “sql only” on and check if you see something unusal there. Reduce the number of rows for this test first.
The only error message that I am getting is the database error which is a violation of a primary key on the second table. Obviously I am expecting this as this is the deliberate error condition that I have created to try and create a rollback for the updates to the two tables.
With the trace options on that you suggested I get:-
Usual startup messages for the job, workflow and dataflow.
Three SQLLOAD logs, one for each table (one is a temp table in a separate data store and two are the ones in the same data store that should be in the same transaction). Each SQLLOAD line says
After the SQLLOAD for the third table (i.e. the second table in the transaction) I get the messages
I have tried removing the try/catch block around the dataflow but this hasn’t made any difference.
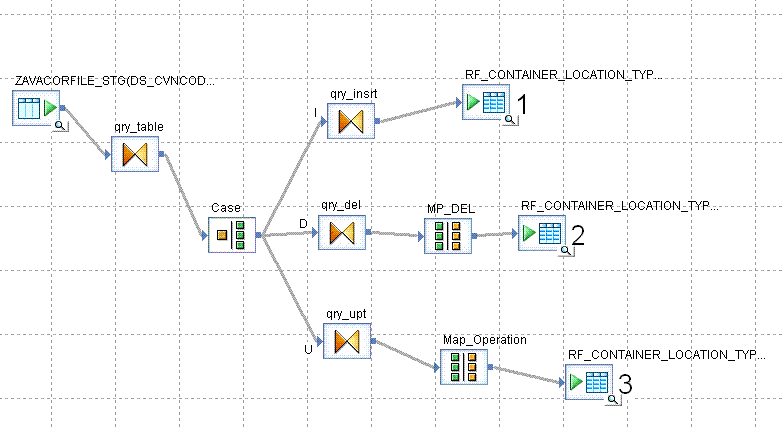
I have a source table with opcode column, which specify if the record has to be Inserted/Deleted/Updated, values (I/U/D)
So for Insert, I am generated keys, for Updated and Delete I have Natural Keys coming from Source which I used to do the necessary operation.
So I have this flow
Source ==> Case ==I====> Key_gen ==> Target A
…==U====>Update ===> Target A, based upon Natural Key
…==D====>DELETE ===> Target A, based upon Natural Key
I have included Transaction Number at the target table level as 1 for Inserts, 2 for Deletes ,3 for Updates
But apart from Inserts, nothing works, there is no Update/Delete operation taking place.
I have Marked Natural_Key as my primary key just before the Map_Operation.
Any idea whats wrong here!
We are on 11.7.3 on Windows Server 2003 and Oracle 10g DB
Source is on Different Schema than Target.
If, I create different DF for Inserts/Updates/Delete then it works!, but not with Transaction Control logic concept.
For these kinds of problems I would always execute the job with the trace_sql_loader flag turned on. Then you can see if updates are executed at all and what values are used.
The natural key is marked as primary key, fine, the loader has to use it, meaning the “use input primary key” option has to be set in the loader options.
One more thing, look at the Map_CDC transform, it is meant for that and it also deals with the case where your source has multiple changes for the same key, e.g. better to insert first and then update a natural key.
My guess: A timing issue and the solution is Map_CDC.
Your source contains this data you said:
I…ALPHAFILEFOLDER…ALPHAFILEFOLDER…Expanding File Folder
I…BIN…BIN…x-ray, cassette, disk, Hold paps bin
I…DRW5-9…DRW5-9…5" Drawer to hold 9 containers
I…SLH25…SLH25…Slide holder - 25 position I…SLIDES DRAWER…SLIDE DRAWER…3" for slide storage
I…SLIDES3-78…SLIDES3-78 …3" drawer 78 alpha/numeric pos. for ES5M slide holders U…SLIDE DRAWER…SLIDE DRAWER…3" for slide storage
D…SLH25…SLH25…Slide holder - 25 position
So you get two rows for the same primary key SLIDE DRAWER, a first insert and a second update. You split the rows into different routes, insert goes in one branch, update into the other.
Now you have two possible effects:
As you did not control it, it could happen the update is executed before the insert. Why not? You have two loaders, each with its own session and no control over the transaction order.
Usually we do array operations, e.g. collect the first 1000 rows and then insert or update them. So in your case the one session collects 1000 inserts, the session of loader2 collects 1000rows for updates and then they are executed in parallel resulting in a database lock as you try to insert and update the same row at the same time.
Turning on transactional loaders is no option either, what if the source is a insert-update-delete-insert-update? Execute the two inserts for the same key twice, then delete them and the update? Certainly not.
With Map_CDC the order of the rows is preserved as no split happens. In fact in the Map_CDC you can specify the order of the statements, e.g. using a timestamp, to make sure the oldest operation is executed first.
Map_CDC works great if you have primary key at the source, or you are not generating PK for new Inserts every time in target table.
In my case, I have to generate Primary key for each new INSERTS using ORA SEQUENCE in to the Target, and use Natural Key for Update/Delete operation!
My DB is ORA, I don’t think I can set something at DB level, so that it will generate PK automatically for each new Inserts, just like Identity column in SQL Server.
Am, I missing some thing here about Map_CDC transformation?
OK, we used Triggers to generate PK, works fine!
If I used ORA_SEQ before the MAP_CDC transform, then I loose key for operation Updates and Deletes.
I actually would use an on-insert-trigger to overwrite the primary key with the sequence number. If an Oracle sequence has to be used instead of key_gen.
 (BOB member since 2004-12-17)
(BOB member since 2004-12-17) (BOB member since 2006-08-19)
(BOB member since 2006-08-19)