I I am having problems with a job which has a table comparison and it is incorrectly sending records as inserts, when they should be updates.
The primary key is 2 columns of nvarchar in the database and my database is case insensitive on SQL Server 2008 R2.
I have seen a lot of people solve similar issues by using the row by row comparison. However I already am using row by row. I see no actual case differences in the data. The source is a customer SAP extractor.
I am at a bit of a loss where to start. I have even turned on ‘input contains duplicate keys’ to see if that helps, but it didn’t.
What options are you thinking of ? I believe the target is using the defaults. Obviously I can set auto-correct on to work around this, but I shouldn’t need to if the table comparison is working.
NB: Could this be causing the issue ? If so ,w hat can I do about it ?
8992 8948 DATAFLOW 20/12/2012 3:14:44 PM The specified locale <eng_us.cp1252> has been coerced to <Unicode (UTF-16)> for data flow
8992 8948 DATAFLOW 20/12/2012 3:14:44 PM <DF_SAP_SD_TR_SALES_DOCUMENT_HEADER_CUSTOM> because the datastore <SAP_ERP> obtains data in <Unicode (UTF-16)> codepage.
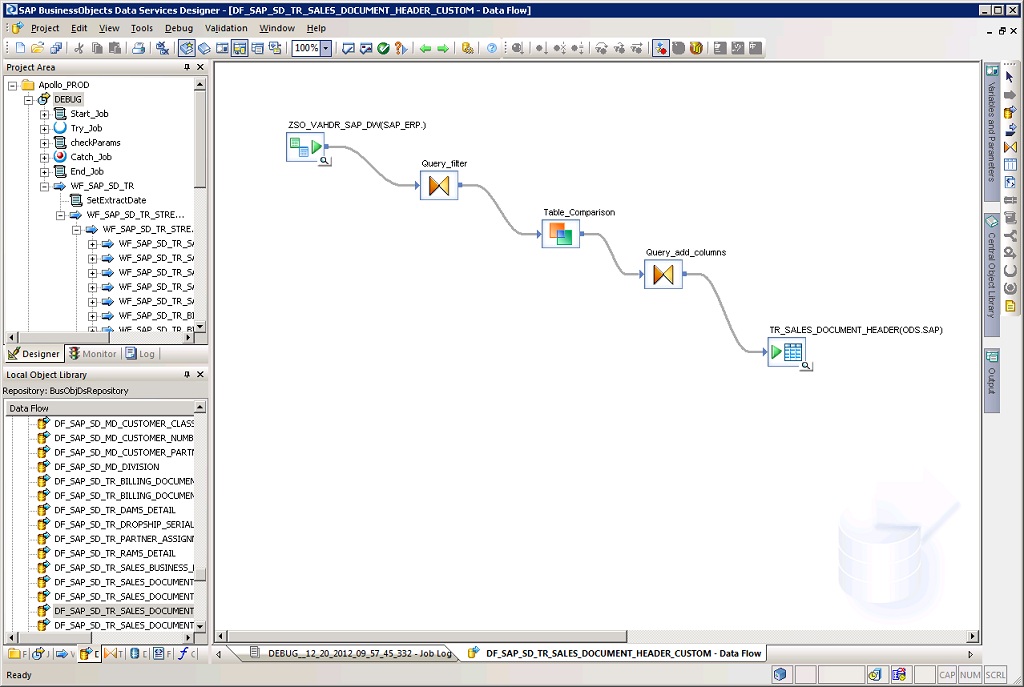
Sorry, I didn’t take the time to look at your second picture. The ONLY thing that comes out of a Query transform are rows with a type of NORMAL. These are inserts. By putting the Query tranform after the Table Compare you wiped out the INSERT/UPDATE operation flags and overwrote them with NORMAL. So everything becomes an insert in your target table.
If you have to perform special actions on insert rows but not on update rows then you have to split them out after the table compare. I split the table compare out to two map operations, one for insert and the other for update. Then, before merging them back together you use additional map operations to turn the normal operations into either INSERT or UPDATE.
The query transform after the comparison just adds auditing information (i.e. inserted_date, etc). If I put those extra columns in my first query, it causes the push-down of the where clause to fail , so I am swapping one issue for another. Do you know how I can preserve the push-down ? The only way I have come up with, is to add a ‘data transfer’ transform between the first query and the second, which works, but shouldn’t be necessary should it ?
It would nice if there was an option on the query transform along the line of ‘don’t attempt push-down’.
You have to split the flow after the Table Compare like I suggested above. It’s not an ideal design but the overhead isn’t much.
Unfortunately, adding audit columns adds overhead in your database as well as your ETL. The less you add the lower the overhead. You could implement the audit population through triggers. But the ETL is still going to want to see those columns (or you get warnings) and I generally frown on implementing triggers in a data warehouse.
A custom transform might be useful here. Now if I just knew how to make one…
 (BOB member since 2012-01-17)
(BOB member since 2012-01-17) (BOB member since 2007-01-10)
(BOB member since 2007-01-10)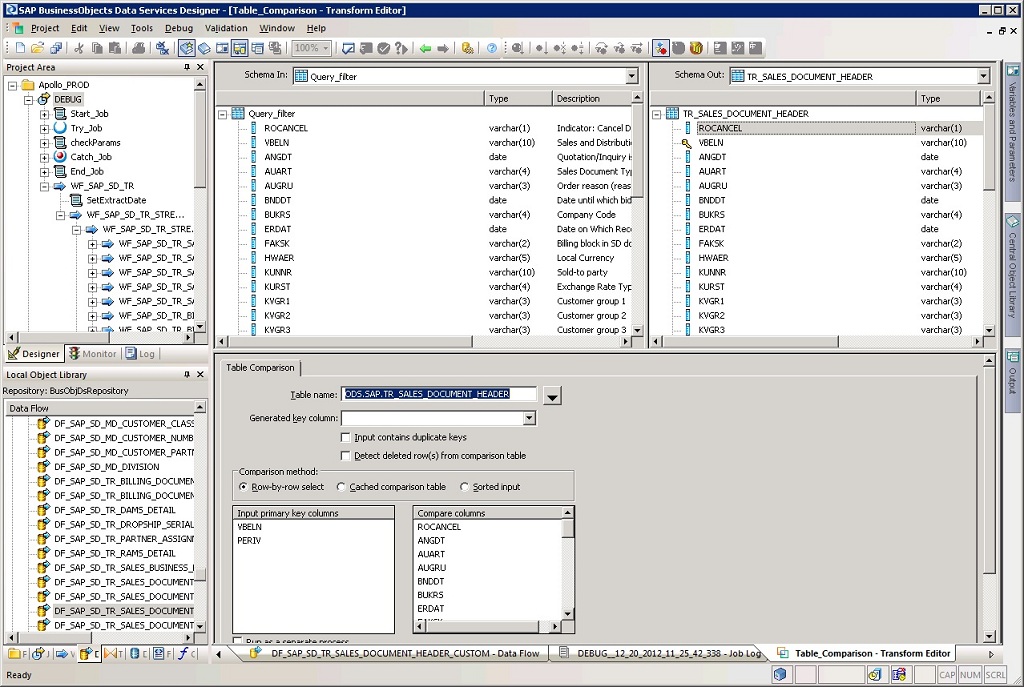
 (BOB member since 2007-09-12)
(BOB member since 2007-09-12)