I want to implement the equivalent of the following SQL in Data Services:
SELECT x.pkey
, COUNT (DISTINCT x.col_1)
, COUNT (DISTINCT x.col_2)
, COUNT (DISTINCT x.col_3)
FROM x_cdb_join_match x
GROUP BY x.pkey
The result of this query is used to transform the input data (coming from the left Data_Transform; if their value is not unique per pkey it is set to null).
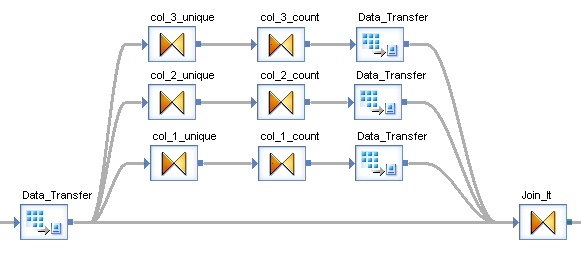
As far as I can see I have to create three of the same flows and join them again (see screen-shot). What makes this worse is that despite the fact that I use Data_Transfer transforms, the queries are not executed in parallel. So this could be done much more efficient. I am looking for suggestions to improve the performance of this. Is there a way to have one Query transform that generates one query like the one above?
Is it the DISTINCT part that is tripping up the Query transform? I’m not clear on where the problem is. If you were unable to code the count(distinct x) in a query transform then I would say just go to a SQL transform. But since you have the Data Transfer tranform in the Dataflow then the SQL transform cannot be used.
This is just part of a larger data flow. This is somewhere in the middle of it, so data is coming from other transforms, in this case separated by a Data_Transfer.
In my opinion SQL transforms are a last resort, and not to be used if alternatives are available. And in most cases when you think you need them I prefer using a database view instead.
The real problem is that I do not know of a way to do a count(distinct col) in oner Query transform. I use two steps:
Select distinct
Count
But that cannot be done for more than one column at a time, whereas SQL can do it in one statement with all the benefits that go with that. So I am actually looking for an efficient solution to execute the functionality from the above query.
Again I run into problems with the count_distinct() function and came across this old topic. What I am trying to achieve is to build the following SQL in BODS, but it will not produce a pushdown of the whole lot ( I believe it should, or can this function not be pushed down to an Oracle 12 database?):
SELECT h.fp_id
, COUNT (
DISTINCT CASE
WHEN o.fp IS NOT NULL THEN o.pos_id
WHEN l.etl_key > 0 THEN NULL
WHEN p.fp IS NOT NULL THEN p.pos_id
END)
aantal_pos
FROM fp_his h
LEFT JOIN pos p
ON p.fp = h.fp_id
LEFT JOIN obj o
ON o.fp = h.fp_id
LEFT JOIN obj l
ON l.pos_id = p.pos_id
GROUP BY h.fp_id
The purpose is to have 3 counters of distinct id’s, with some logic for the first. All of this can be written into a single decode():
Again I run into problems with the count_distinct() function and came across this old topic. What I am trying to achieve is to build the following SQL in BODS, but it will not produce a pushdown of the whole lot ( I believe it should, or can this function not be pushed down to an Oracle 12 database?):
SELECT h.fp_id
, COUNT (
DISTINCT CASE
WHEN o.fp IS NOT NULL THEN o.pos_id
WHEN l.etl_key > 0 THEN NULL
WHEN p.fp IS NOT NULL THEN p.pos_id
END)
aantal_pos
FROM fp_his h
LEFT JOIN pos p
ON p.fp = h.fp_id
LEFT JOIN obj o
ON o.fp = h.fp_id
LEFT JOIN obj l
ON l.pos_id = p.pos_id
GROUP BY h.fp_id
The purpose is to have a counter of distinct id’s, with some logic applied. All of this can be written into a single decode():
Is it possible that the LEFT joins are tripping it up? I’ve seen DS produce some utterly stupid queries that don’t seem to be close to what I intended. Simplifying it sometimes helps. Breaking it up into separate (but linked) Query transforms can also help.
For example, I never code a gen_row_num_by_group() in the same Query transform that I do the Order By that the by_group is counting on. I have to code the Order By in the first Query transform and the gen_row_num_by_group() in the second Query transform.
 (BOB member since 2007-09-12)
(BOB member since 2007-09-12) (BOB member since 2008-09-02)
(BOB member since 2008-09-02)