We have a dataflow which extracts data from a source file, pivots the data, and then loads data into a target table. This dataflow will be executed many times in the same job. When the dataflow runs, we’re finding that it degrades in performance after each iteration within the job.
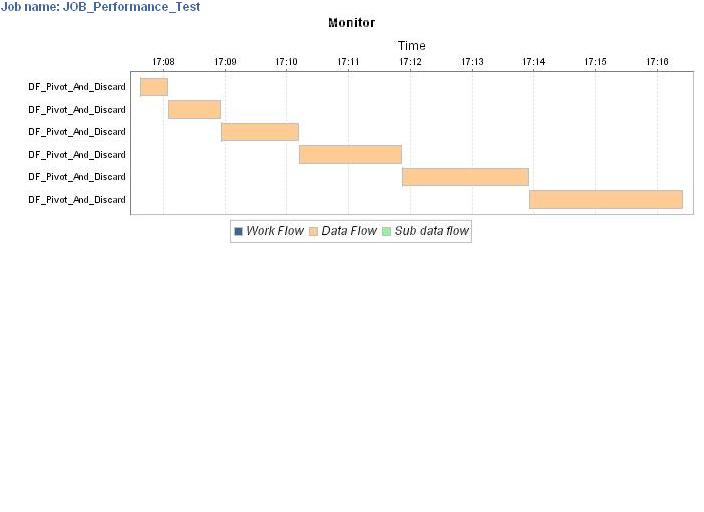
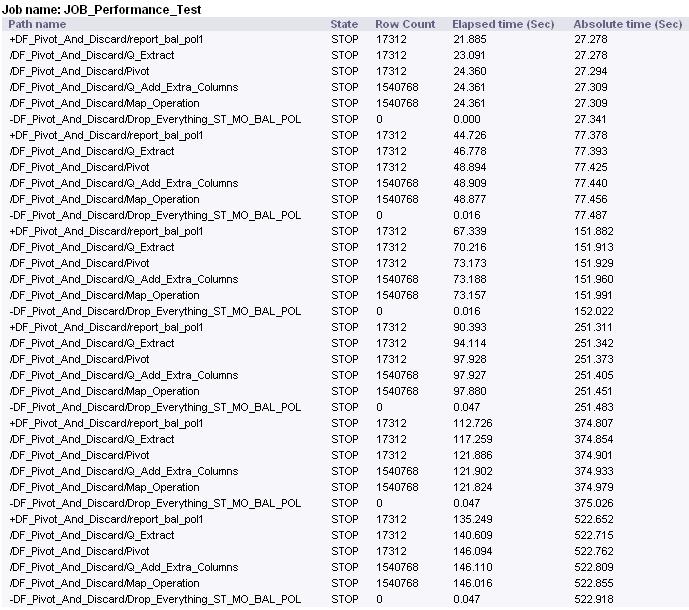
We’ve narrowed this down to being caused by the Pivot transform by mocking up a dataflow which does nothing but read, pivot, and then discard all rows using the Map operation. Then the dataflow is executed sequentially 6 times, with results as follows;
Each dataflow extracts from the same source file & processes identical numbers of rows.
Does anyone else experience this behaviour, and are there any suggested workarounds? We don’t want to split this into multiple jobs if we can avoid it.
Thanks for this. I’ve just given it a try - truncating the AL_STATISTICS table after each dataflow execution. It improves performance marginally (1-2s off each execution), but doesn’t prevent the slowdown…
We have discussed that internally and figured we need one addition test first.
Please add a Map_Operation Transform right after the Pivot transform where you discard normal rows. As you are saying the root cause is the Pivot, you would see the same kind of behavior.
However if the pivot is not the problem but e.g. the target database for whatever reason…
This is already in place - the stats above are for a dataflow which already does this.
I’ve also just created another dataflow which does a similar thing (read from a source table, pivot, Map_Operation to discard all rows) but from a SQL Server database, in case it was a problem with the source file (FoxPro). In this case, the performance also degraded.
8s → 14s → 19s → 25s → 31s
HOWEVER - and this is the bit that has totally confused me… on Monday morning when I re-ran the same job as per previous posts, it executed much more quickly, at a constant rate of ~2.5s for each execution of the dataflow. Same data, same job.
Re-running today, the job is back to its previous performance levels. I’ve tried re-booting the server & running the job immediately after the re-boot, but it is still back to its previous, degrading performance levels. Monitor output is attached for comparison.
To clarify - are you using Pivot or Reverse Pivot?
What version of DI?
I just tried reproducing this under 11.7.3, and couldn’t. In my test, I used a Row Generation transform as a source, rather than reading from a table, so I could be sure to eliminate any database interactions as an issue.
Thanks for this - we’re using 11.7.3. The above is using Pivot, rather than Reverse Pivot.
I’ve tried with Row_Gen instead of a source table & performance is consistent for each iteration… so I’ve also created a new dataflow which has nothing other than;
Source Table → Discard all Rows
… and this does have degrading performance when run multiple times in the same job. So looks like this is nothing to do with Pivot after all I should probably have tried this earlier, rather than just trying from a different source type.
Next step, I’ve done the same test (Source Table → Discard all rows) for the following source types;
SQL Server 2005 - performance degrades after each iteration
FoxPro (via ODBC)- performance degrades after each iteration
iSeries DB2 (via ODBC) - performance is consistent
So it seems that this only occurs for some data sources. As the ODBC performance is consistent from iSeries ODBC, but degrades from FoxPro ODBC, it looks to be specific to the driver rather than BODI?
Either way, it would be useful to know whether the same test produces similar results for anyone else extracting from SQL Server 2005/FoxPro - to narrow down whether it may be something to do with our environment rather than the drivers themselves.
We use SQL server as our source/target and don’t experience the same slowdowns.
You should monitor the job server (hardware/OS) during this process to see if anything looks odd.
Maybe try disabling antivirus software on the job server.
Moreover, try taking the generated SQL from the dataflow, and run it consecutive times in SQL server itself (query analyzer), just to prove that it’s DI and not the database server.
 (BOB member since 2004-12-17)
(BOB member since 2004-12-17) (BOB member since 2005-07-28)
(BOB member since 2005-07-28)
 (BOB member since 2004-01-30)
(BOB member since 2004-01-30)