dt -num -subkey -assignkey
01.01.2009 - 100 - k - a
04.01.2009 - 100 - k - a
08.01.2009 - 200 - k - b
15.01.2009 - 200 - k - b
17.01.2009 - 200 - k - b
19.01.2009 - 100 - k - c
20.01.2009 - 100- k - c
03.01.2009 - 300 -j - a
05.01.2009 - 300 - j - a
06.01.2009 - 400 - p - a
What I need to do is generate assignkey based on the num and subkey.
Please can you giude me to generate this format using BODS.
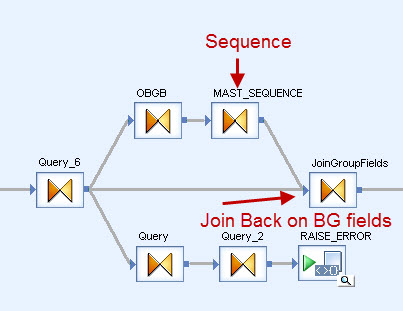
if you do an orderby+groupby on your group fields, then add a sequence number(gen_row_num()) … then join that back on your group fields in another query … walla
thanks for your reply, I did not understood how to join back on group fields. If you have any example to explain will be very helpful. Thanks for your help in advance.
great thanks , it is working half way though, what I am getting is ;
dt -num -subkey -assignkey
01.01.2009 - 100 - k - a
04.01.2009 - 100 - k - a
08.01.2009 - 200 - k - b
15.01.2009 - 200 - k - b
17.01.2009 - 200 - k - b
19.01.2009 - 100 - k - c
20.01.2009 - 100- k - c
03.01.2009 - 300 -j - d - instead of a which is my requirement when new subkey begins
05.01.2009 - 300 - j - d - instead of a which is my requirement when new subkey begins
06.01.2009 - 400 - p - e - instead of a which is my requirement when new subkey begins
Thanks for your reply, assignkey resets when the subkey changes.when subkey changes, assignkey resets and again begins with ‘a’ and increments to ‘b’ when ‘num’ changes … hope this explains my requirment.
Ok, I mostly see what you’re looking for I just dont understand the sortation.
if you did a group by on subkey,num and then did a gen_row_num_by_group(subkey,num) … converting that to an alpha( chr(64+grbg) that would give you your assignkey.
Hi I cannot use group by gen_row_num_by_group(subkey,num) because then it will group 01.01.2009 - 100 - k - a
04.01.2009 - 100 - k - a
08.01.2009 - 200 - k - b
15.01.2009 - 200 - k - b
17.01.2009 - 200 - k - b 19.01.2009 - 100 - k - c
20.01.2009 - 100- k - c
highlighted rows above (100 - k) into 1 group (100-k-a) whereas I want them to be in 2 groups (100-k-a) and (100-k-c) as per order of their appearance based on dates.
By using group by (num-subkey) it is failing my need to generate them as 2 different groups (100-k-a) and (100-k-c) . hope it helps, let me know if you didn’t understood anything in here. Thanks for helping me with this query.
This seems like it should be a lot easier than it is. Like if you could conditionally gen_row_by_group() and look at the previous row value.
doing it in Python would be really easy.
IH = open(r'd:\desktop\testfile.txt','r')
saveSubkey = None
assignKey = 0
tupSave = None
for record in IH:
date,num,subkey,req = record.rstrip('\n').split('-')
tupRec = (subkey,num)
if tupSave is None:
assignKey = 0
tupSave = (subkey,num)
elif tupRec != tupSave:
assignKey += 1
tupSave = tupRec
if saveSubkey is None:
saveSubkey = subkey
elif subkey != saveSubkey:
assignKey = 0
saveSubkey = subkey
print date,num,subkey,req,chr(65+assignKey)
IH.close()
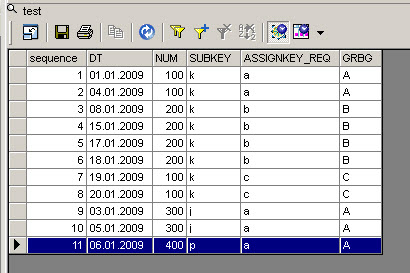
01.01.2009 100 k a A
04.01.2009 100 k a A
08.01.2009 200 k b B
15.01.2009 200 k b B
17.01.2009 200 k b B
19.01.2009 100 k c C
20.01.2009 100 k c C
03.01.2009 300 j a A
05.01.2009 300 j a A
06.01.2009 400 p a A
Pretty sure this will do the trick. It gets a bit inefficient as the quantity increases but it looks to work as requested.
it uses a gen_row_num_by_group, selects off the 1st member of each group then reverses the sortation and fills in the Null assign keys with the closest sequence. Its pretty ugly.
Congrats!! I tried using the previous row but forgot about assigning it to a variable. It returns null on the second subordinate record, which led me to my spaghetti dataflow.
Yeah, thanks for your suggestions, it helped me to progress, great relief it got sorted and hence I landed on another query. Now I need to access next row value and BODS does not provide any function for next row like it has for Previous_Row_Value ()
If you reverse your sortation, previous row becomes next row. I did that in my spaghetti flow to get around storing the previous row into a global variable.
When you sequence your rows, you can access the next/previous rows by joining on the sequence ±1.

 (BOB member since 2009-10-27)
(BOB member since 2009-10-27)