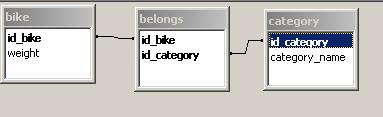
I have setted up a universe that has the same structure, and created three objects :
Dimension ‘Bike ID’ : wich is the id_bike field from the bike table.
Dimension ‘Category’ : wich is the category_name field from the category table.
Indicator ‘Bike weight’: defined as sum(weight), weight field from the bike structure.
Then I build a report bringing the objects ‘Bike’ and ‘Bike weight’, plus a filter on ‘Category’ to select only the bikes from two categories i specify (cat1 and cat2).
I sould get the weight of each bike that belongs to the two categories selected.
The problem is that the weight of the bikes that belong to the two categories (cat1 AND cat2) are counted twice (twice bigger as they should be).
When looking at the SQL command generated by deski, we can imagine where the problem comes from :
SELECT bike.id_bike, SUM(bike.weight)
FROM bike,belongs,category
WHERE bike.id_bike=belongs_id_bike
AND belongs.id_category=category.id_category
AND category.category_name in ('cat1','cat2')
GROUP BY bike.id_bike
If we execute this command in sqlplus (or any sql editor), removing the GROUP BY and changing SUM(bike.weight) by bike.weight, we can see that the lines corresponding to the bikes that belong to the two categories show up twice. Now we can imagine that when grouping and summing, the weight is counted double.
One possibility would be to put a ‘distinct’ on the select, but it doesn’t work with the GROUP BY.
SELECT bike.id_bike, bike.weight
FROM bike,belongs,category
WHERE bike.id_bike=belongs_id_bike
AND belongs.id_category=category.id_category
AND category.category_name in ('cat1','cat2')
you will get
id_bike | weight
1 | 6
2 | 5
2 | 5
now the same with the indicator (the group by and the sum)
SELECT bike.id_bike, SUM(bike.weight)
FROM bike,belongs,category
WHERE bike.id_bike=belongs_id_bike
AND belongs.id_category=category.id_category
AND category.category_name in ('cat1','cat2')
GROUP BY bike.id_bike
From your data it shows that bike 2 falls into 2 categories. If you don’t take the category to the group by clause, it will create doubles.
In your sample it appears you are only interested in the bikes and their respective weights, all coming from the bike table.
All you need is to get the id_bike from all selected categories
SELECT id_bike, weight
FROM Bike
WHERE id_bike IN
(SELECT id_bike
FROM Category, Belongs
WHERE Category.id_category = belongs.id_category
AND category.category_name in ('cat1', 'cat2')
)
well, you can also try to use the Oracle analytics functions (first value i believe, I have been out of Oracle for a while now), but I don’t know whether this is easy to implement these in BO.
i have tested it, and it works in that example
i am trying to think of situations where this could bring problems, but i don’t see any. what do you think ?
do you need to define the weight as a measure? or can you define it as a dimension object, thus removing the group by.
Your solution might very well work.
But when you look at it, say 1 year from now (or some collegaue of yours), will you still understand why you used this construct?

 (BOB member since 2008-10-02)
(BOB member since 2008-10-02)