Using DI 11.5
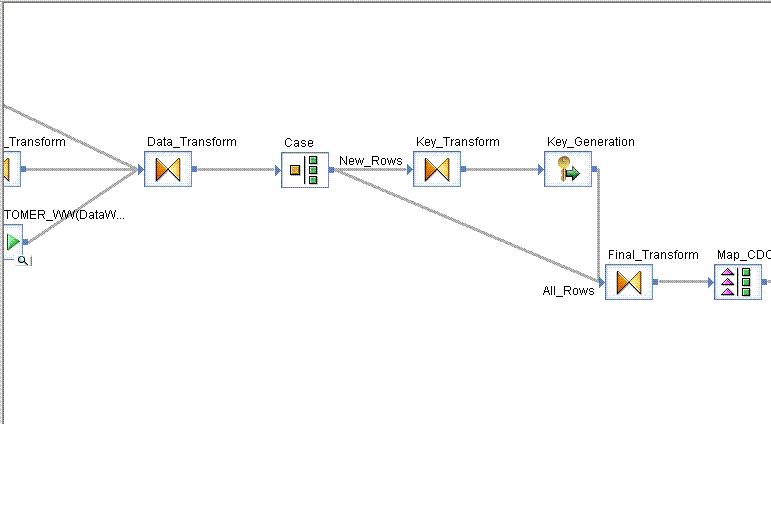
We use a Case transform to delineate new rows from all rows, pass the new rows into the Key Generation transform, and then rejoin the new and all rows in a third transform, using the keys from the Key Generation transform with the remainder of the data from the all rows branch of the Case.
The problem I’m running into is that, in one job in particular, DI is doing a Cartesian join as soon as it exits the Case statement, attempting to send 118500 squared records into the Key Generation, which overloads it, causing errors. I’ve tried replacing the Case transform with a Query transform, parsing out only the new records, and sending that along to the Key Generation transform, but it’s still having issues.
All of the rows are new, as this is a new job, and it’s going to populate right around 118500 rows. Is there some way to tell DI not to attempt any joins until the Transform where the new_rows branch is joined to the all_rows branch, and not immediately out of the Case Transform?
BTW, I stumped our resident DI answerman with this one, as he has no clue why it’s doing what it is doing…
jamonwagner  (BOB member since 2007-03-14)
(BOB member since 2007-03-14)
 (BOB member since 2004-12-17)
(BOB member since 2004-12-17)